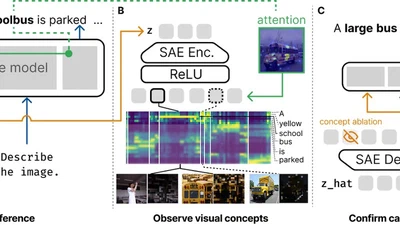
VisualScratchpad: Grounding Visual Concepts in Large Vision Language Models
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
hyesu-lim
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
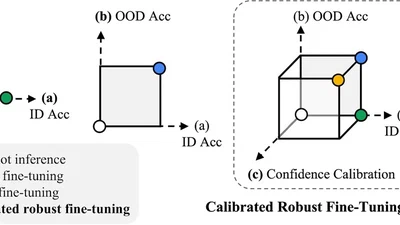
Calibrated, robust fine-tuning method for vision-language models that preserves uncertainty estimates under distribution shift.