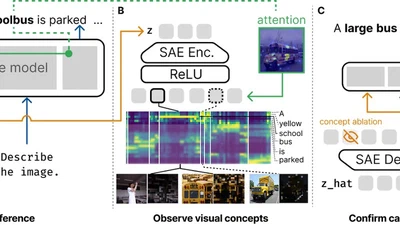
VisualScratchpad: Grounding Visual Concepts in Large Vision Language Models
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
hyesu-lim
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
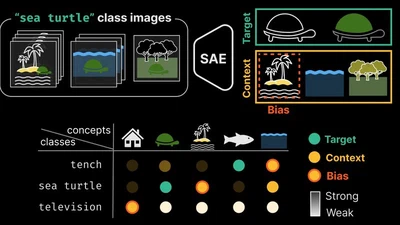
Characterizes dataset bias by disentangling visual concepts learned by sparse autoencoders on vision models.
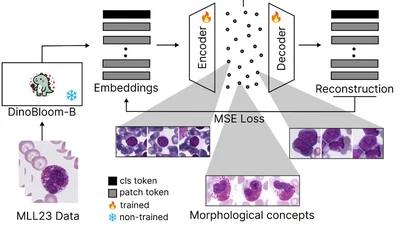
Sparse autoencoders for interpretable single-cell embeddings in hematology.
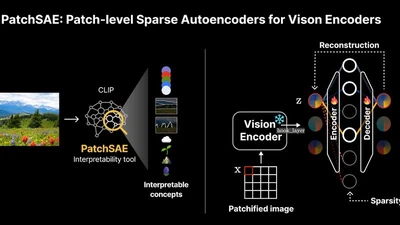
Sparse autoencoders expose how visual concepts are selectively remapped when vision models adapt to new domains.
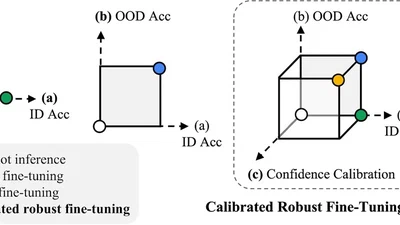
Calibrated, robust fine-tuning method for vision-language models that preserves uncertainty estimates under distribution shift.
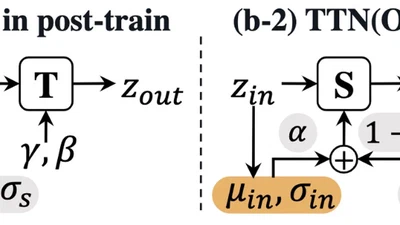
Domain-shift aware batch normalization layer that improves test-time adaptation under distribution shift.
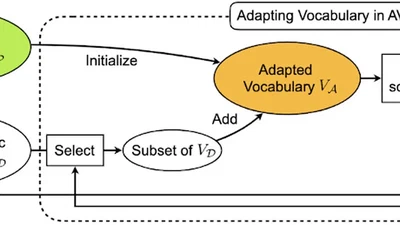
A vocabulary adaptation strategy for pretrained language models targeting downstream domains.