Publications
 ICLR 2026 Trustworthy AI Workshop
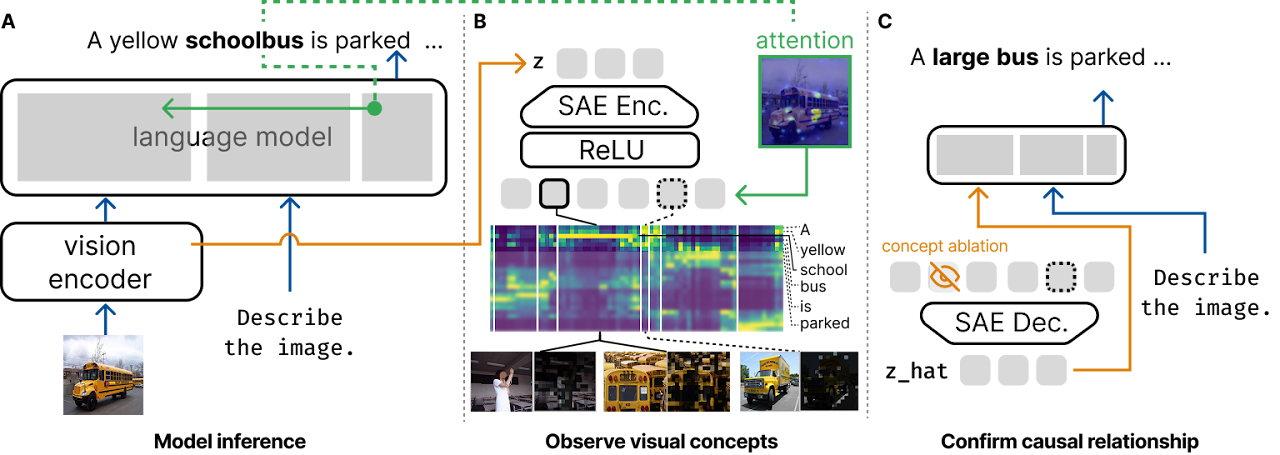
ICLR 2026 Trustworthy AI WorkshopVisualScratchpad: Grounding Visual Concepts in Large Vision Language Models
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
 NeurIPS 2025
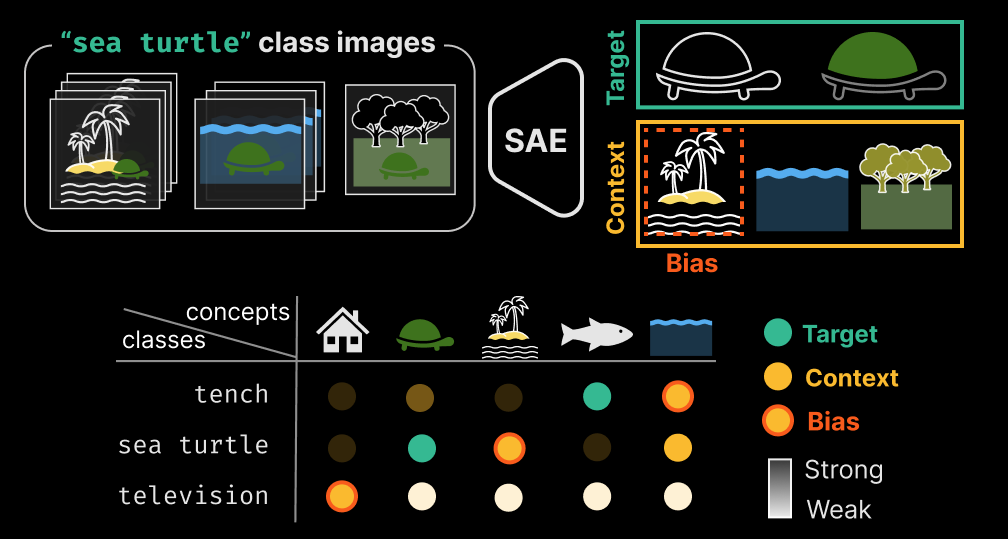
NeurIPS 2025ConceptScope: Characterizing Dataset Bias via Disentangled Visual Concepts
Characterizes dataset bias by disentangling visual concepts learned by sparse autoencoders on vision models.
 MICCAI 2025
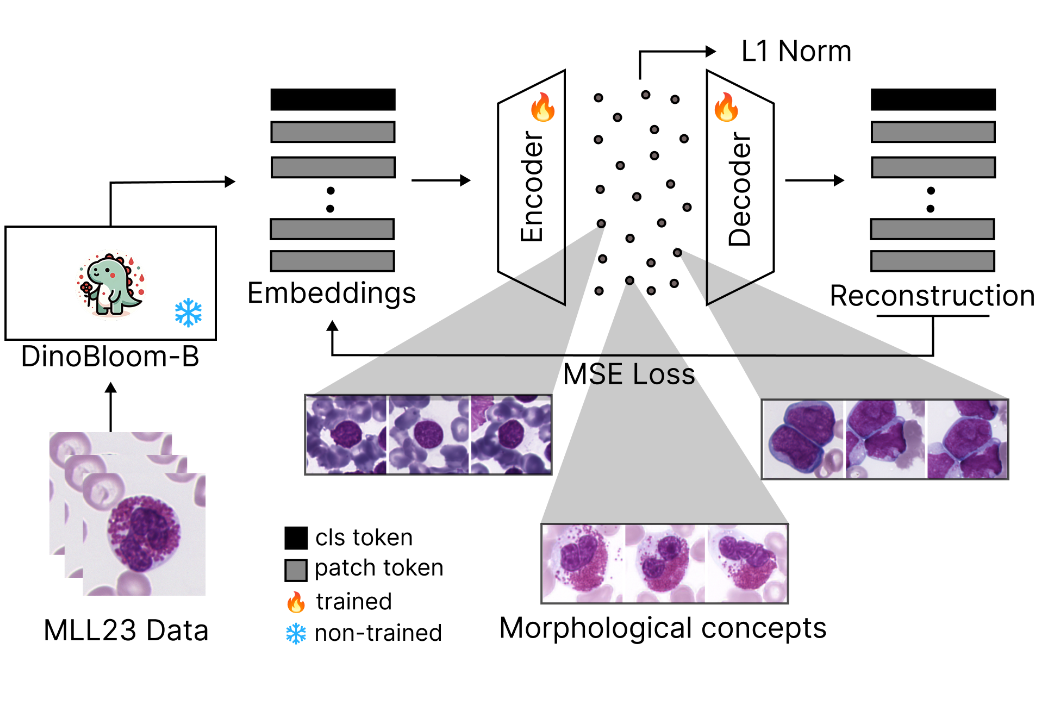
MICCAI 2025CytoSAE: Interpretable Cell Embeddings for Hematology
Sparse autoencoders for interpretable single-cell embeddings in hematology.
 ICLR 2025
ICLR 2025Sparse Autoencoders Reveal Selective Remapping of Visual Concepts During Adaptation
Sparse autoencoders expose how visual concepts are selectively remapped when vision models adapt to new domains.
 NeurIPS 2024
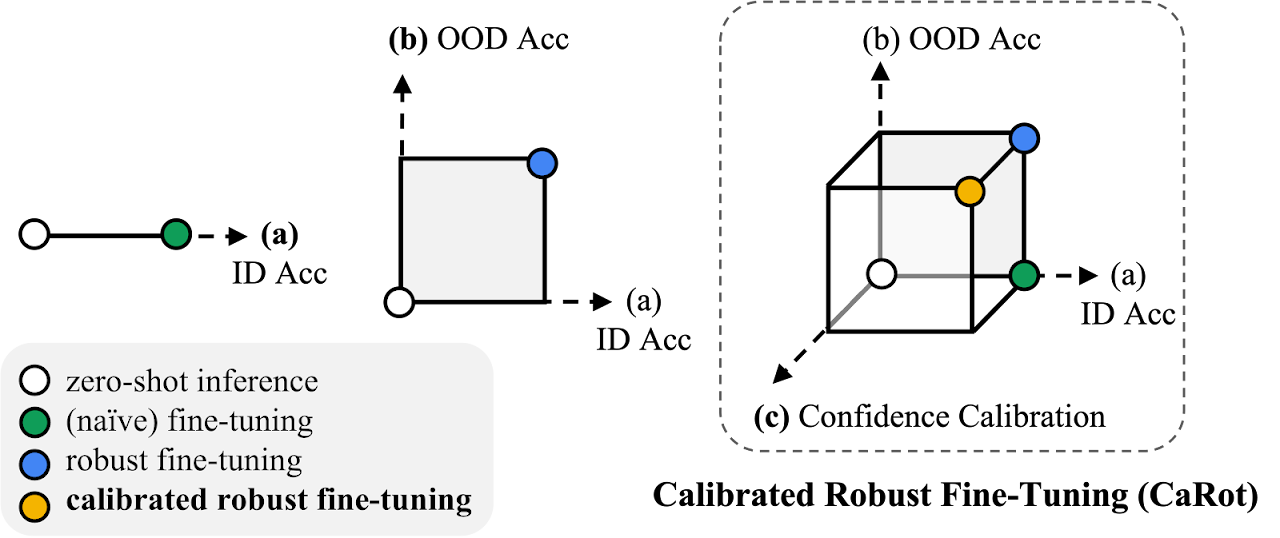
NeurIPS 2024Towards Calibrated Robust Fine-Tuning of Vision-Language Models
Calibrated, robust fine-tuning method for vision-language models that preserves uncertainty estimates under distribution shift.
 ICLR 2023
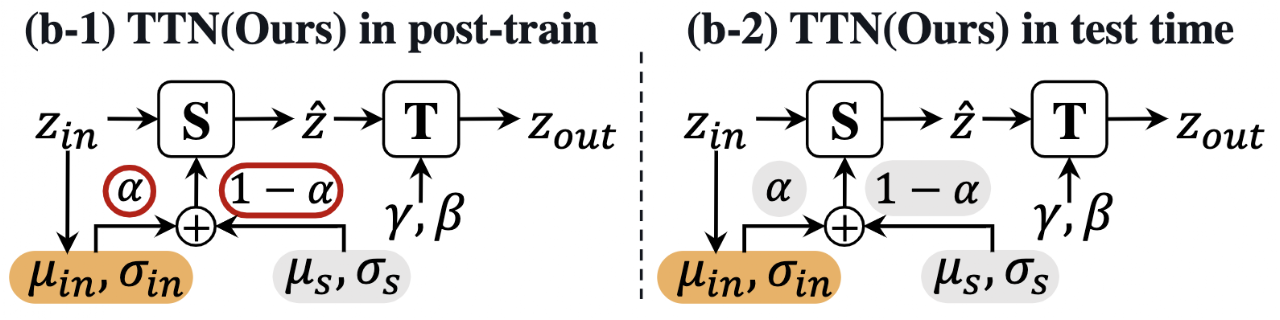
ICLR 2023TTN: A Domain-Shift Aware Batch Normalization in Test-Time Adaptation
Domain-shift aware batch normalization layer that improves test-time adaptation under distribution shift.
 EMNLP 2021
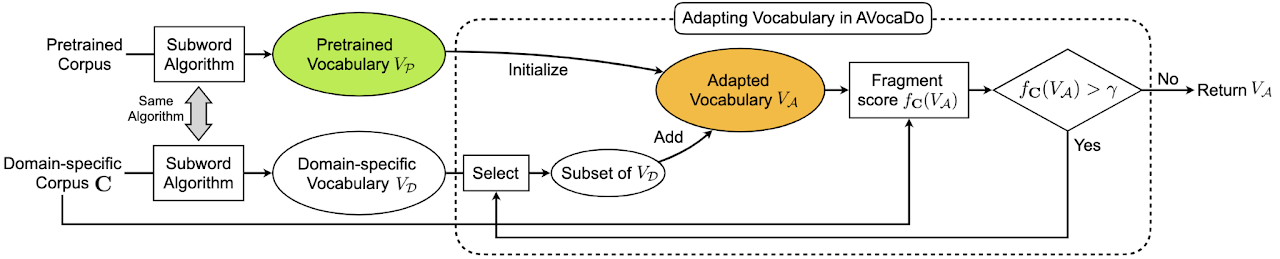
EMNLP 2021AVocaDo: Strategy for Adapting Vocabulary to Downstream Domain
A vocabulary adaptation strategy for pretrained language models targeting downstream domains.