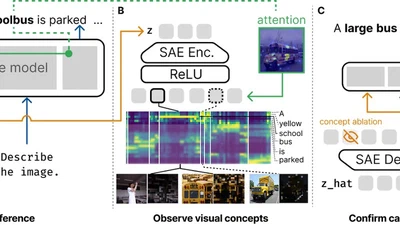
VisualScratchpad: Grounding Visual Concepts in Large Vision Language Models
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
hyesu-lim
Grounding visual concepts in large vision-language models via a attention-based linking mechanism.
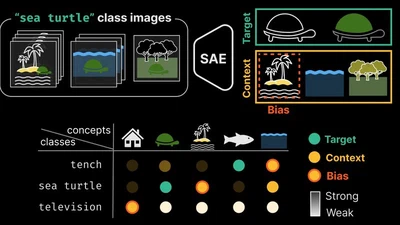
Characterizes dataset bias by disentangling visual concepts learned by sparse autoencoders on vision models.